Interface for ΔG Genetic Data Analysis
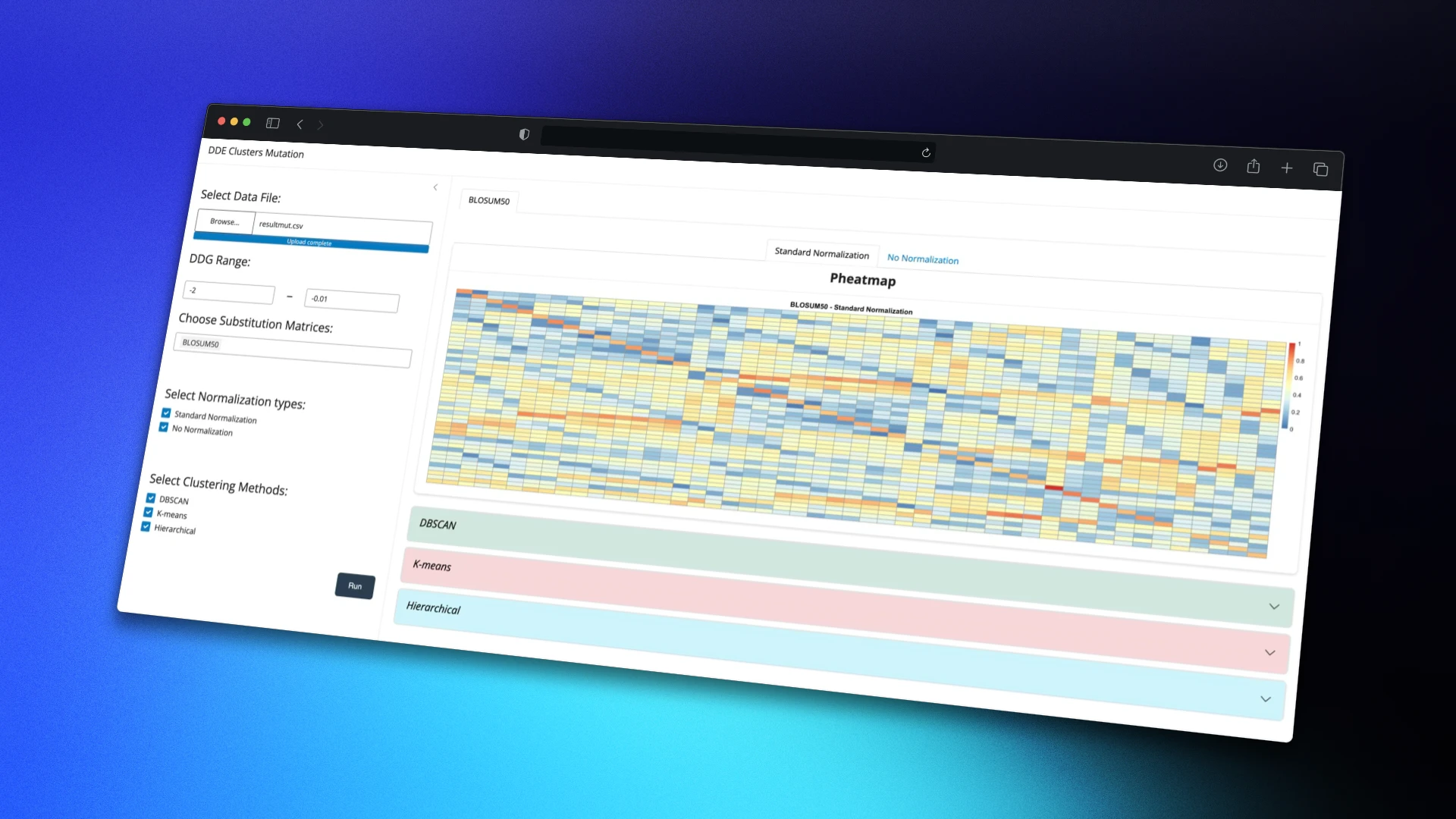
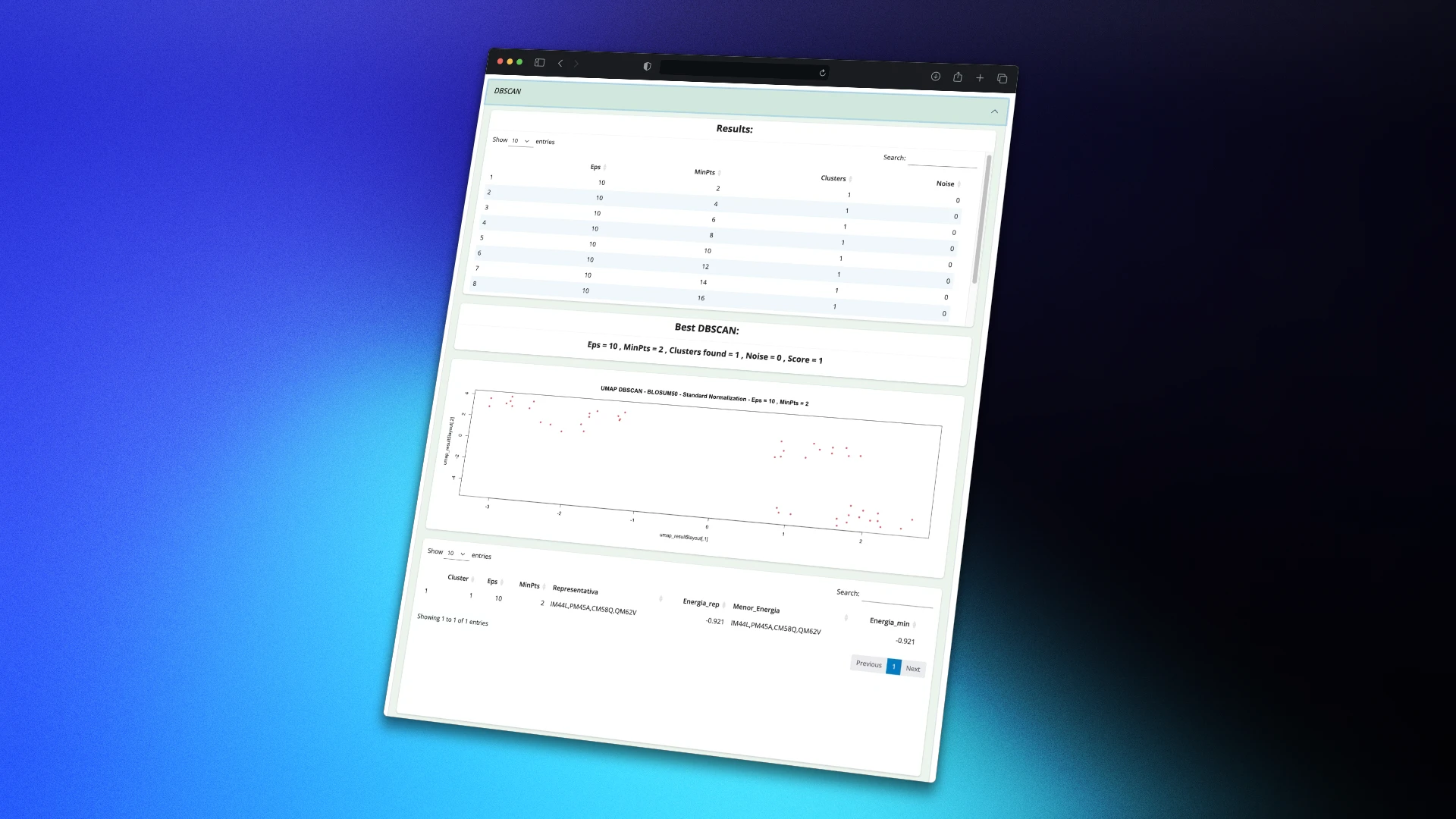
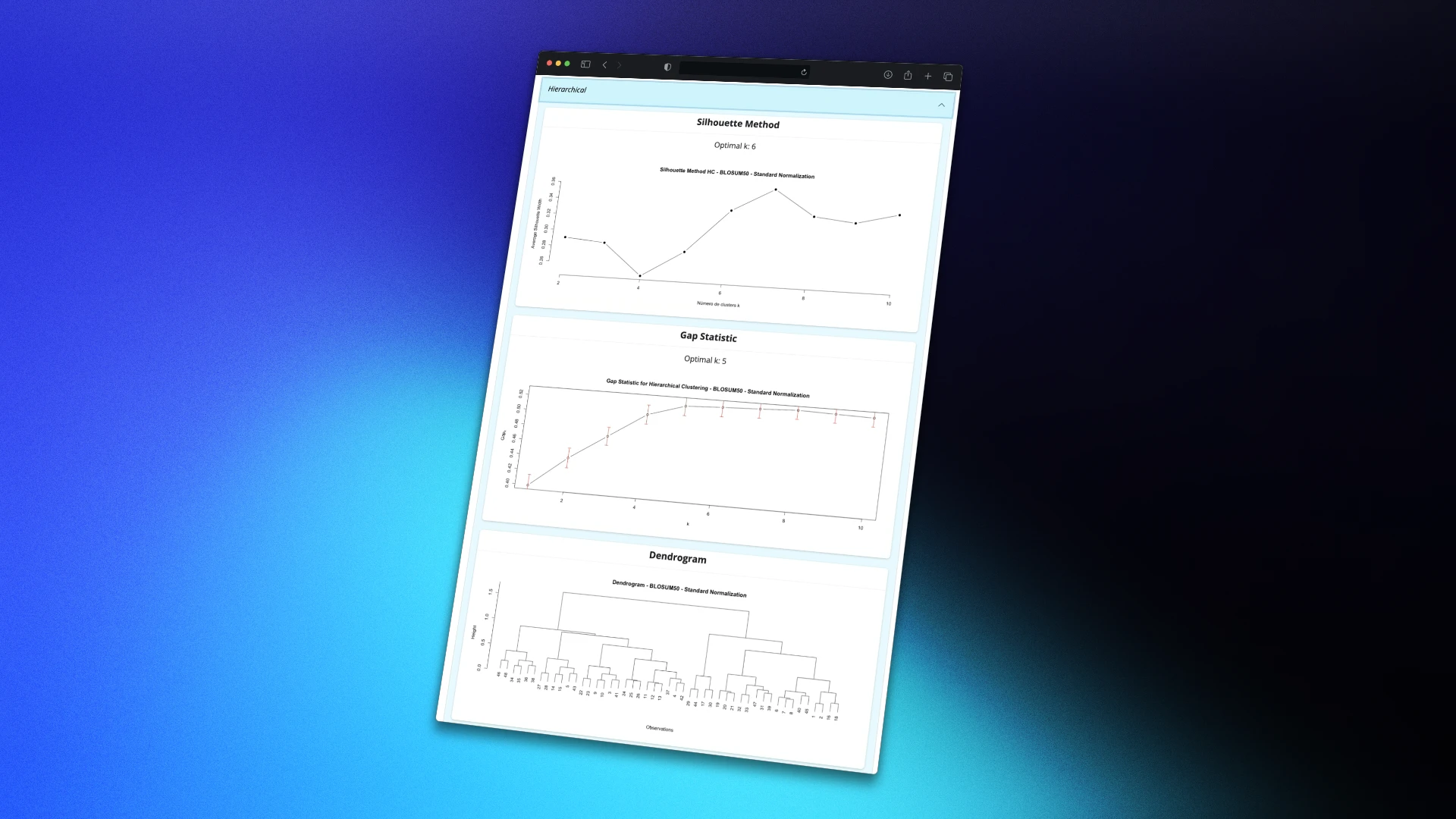
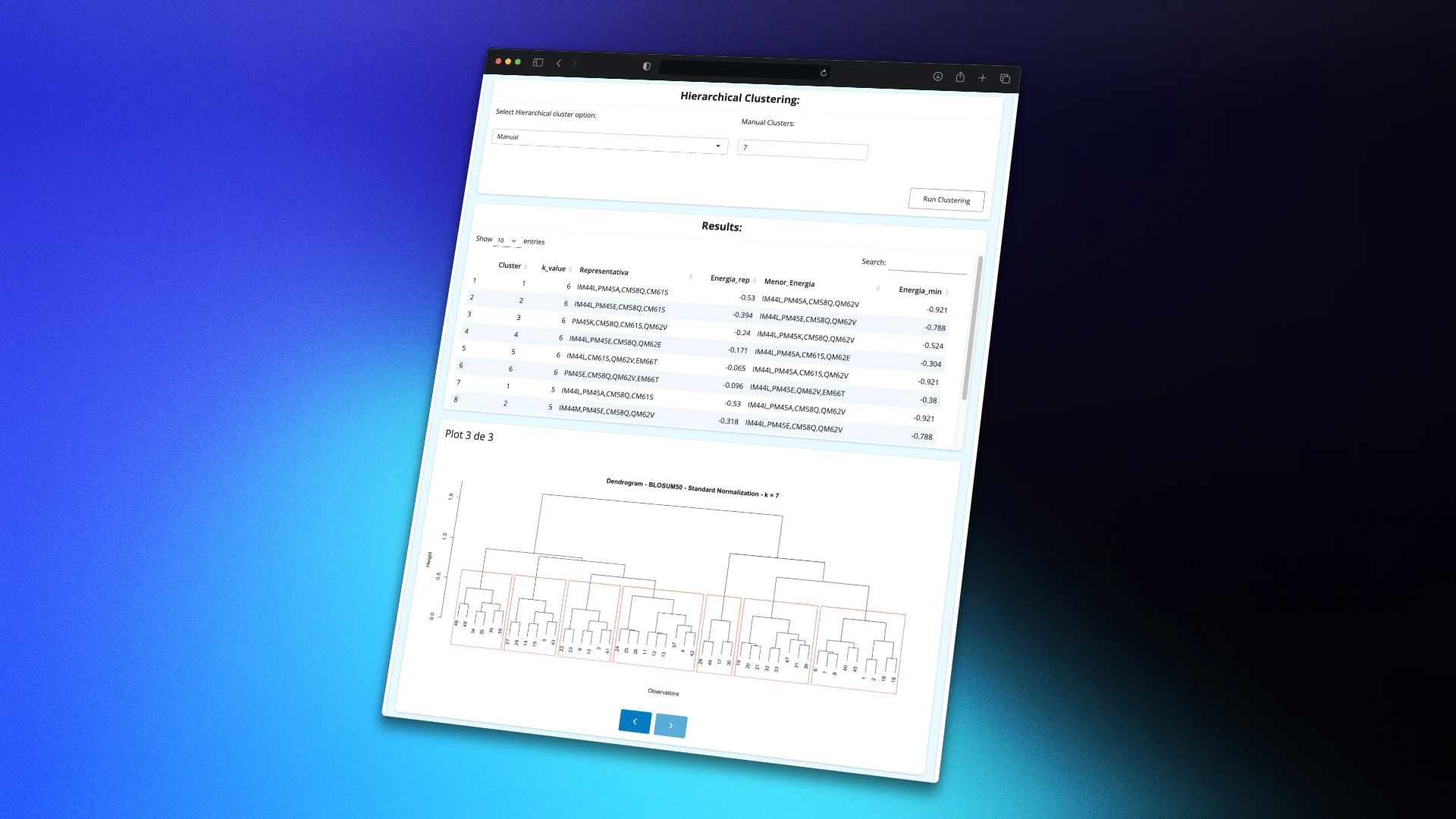
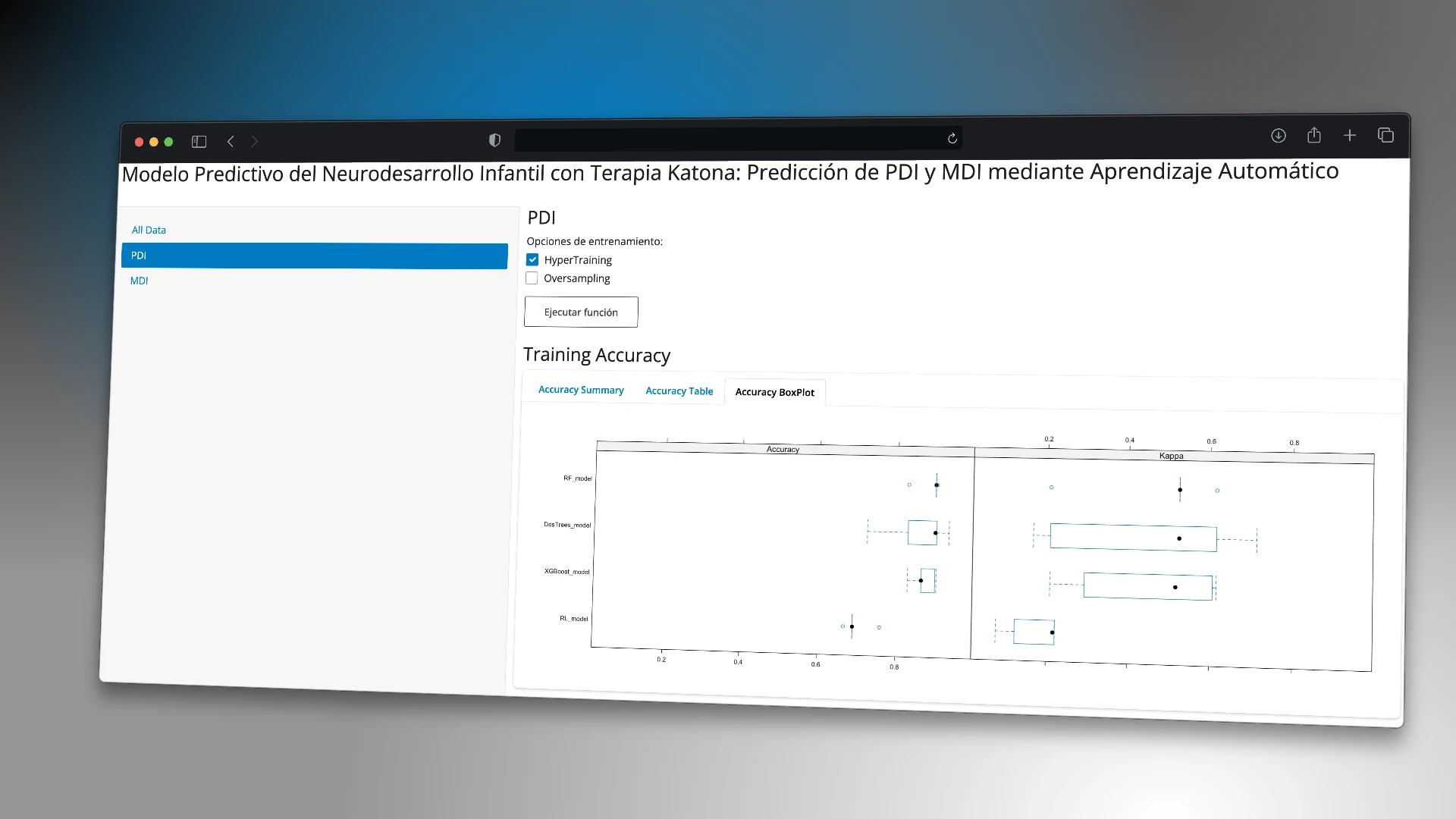
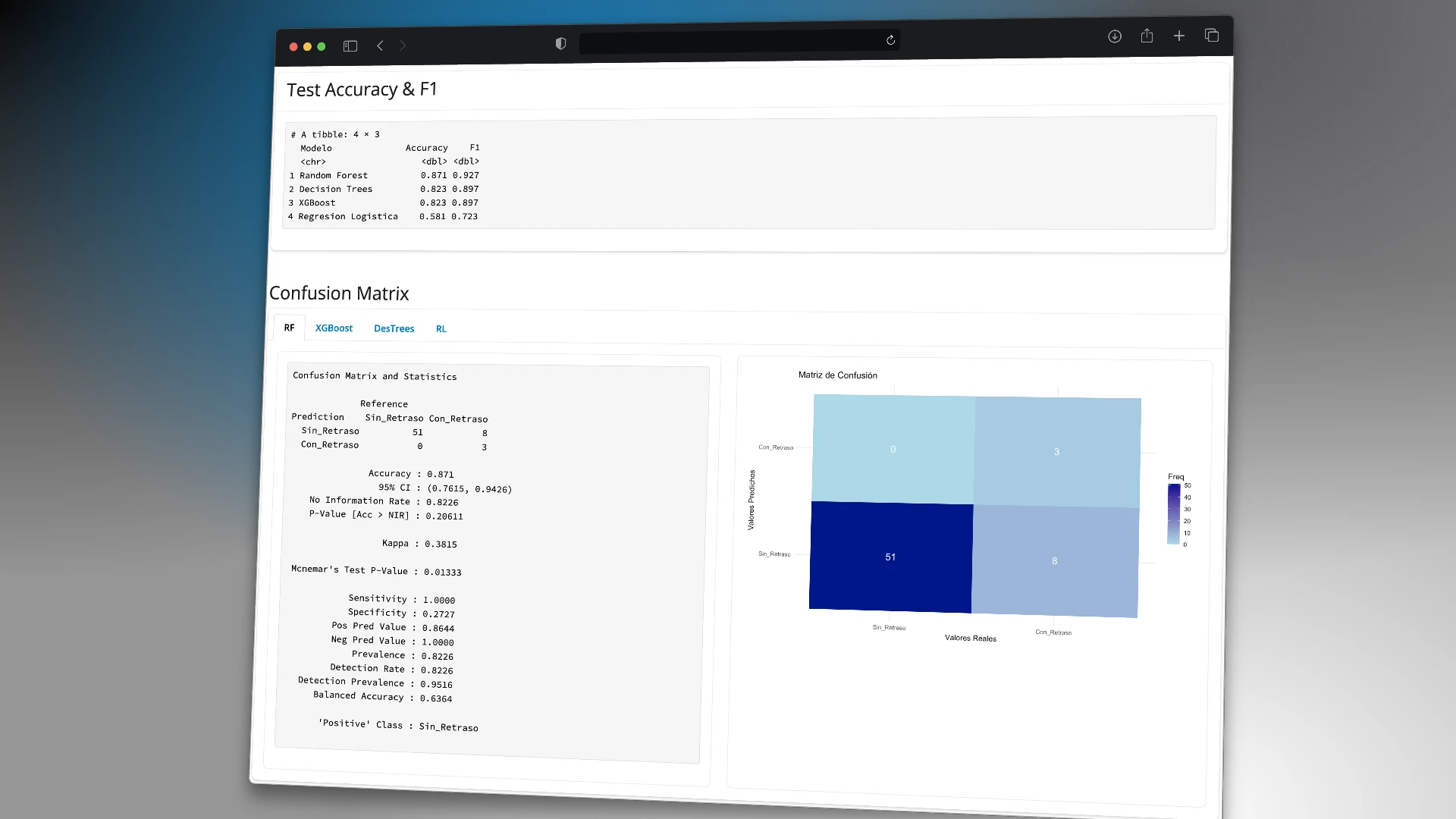
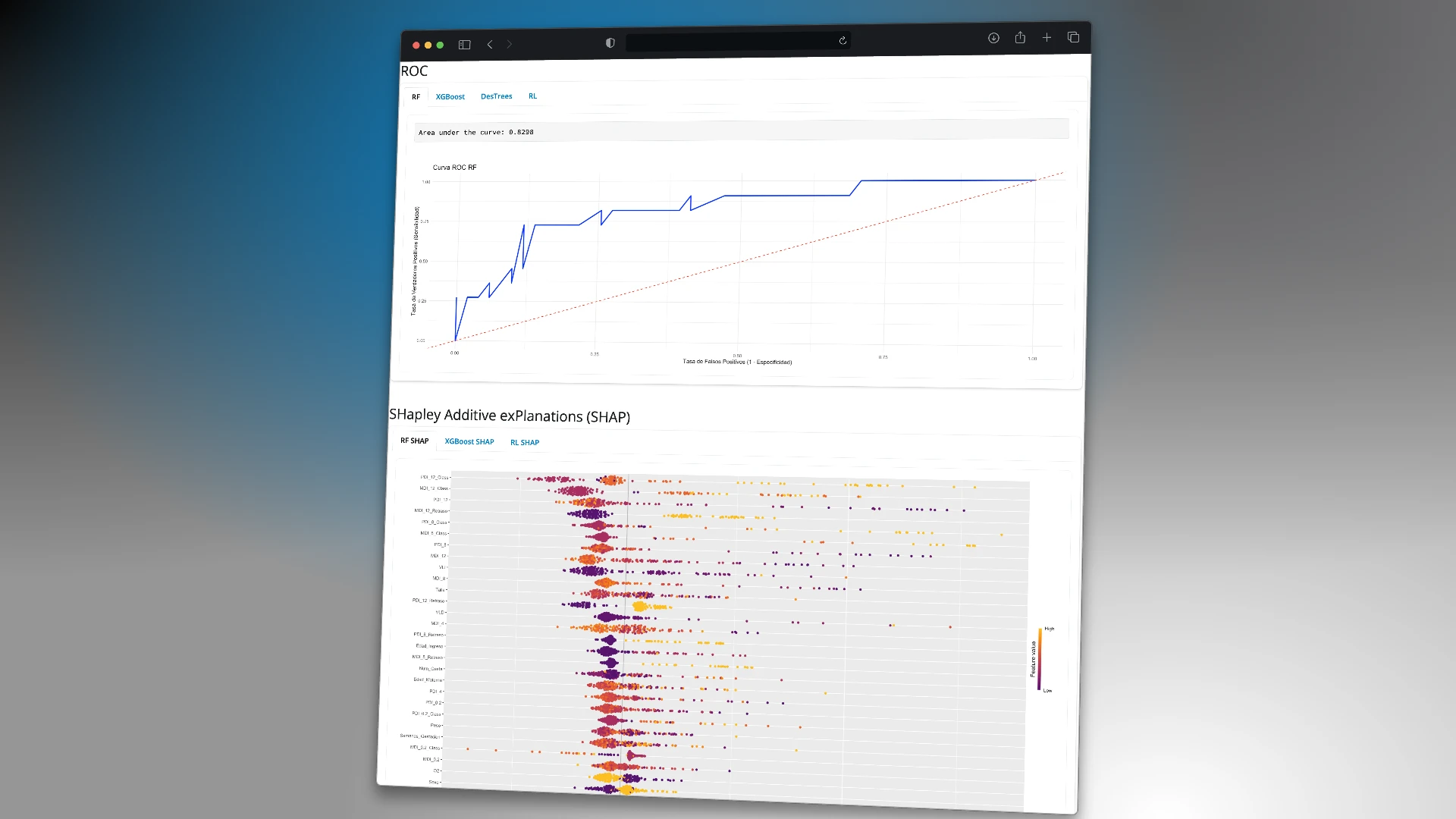
Developed an interactive R Shiny interface for the analysis of genetic sequences with energy values (ΔG), enabling sequence grouping by similarity, application of both automatic and manual clustering methods, and exploration of results through interactive visualizations such as dendrograms. Additionally, a tool was implemented to generate sequence combinations for structural biology analysis. The project aims to facilitate access to advanced genomic analysis tools for researchers and healthcare professionals without requiring advanced programming skills.
- R language
- Shiny